Hey everyone! To reiterate my opening sentence from last time: It’s been a while since I last posted, but don’t worry, I’ve been keeping busy.
Normally, I’d dive into the technical details, but not this time. It’s been too long, there’d be too many of them, and even I don’t remember them all. I’d have to read through and summarize ~1200 commits, and if I wanted to spend my time doing that kind of thing, I’d get a job as an LLM.
Instead, how about we skip to the part everyone cares about? The Run 1 and Run 2 remakes are both close to completion, with all levels (plus Infinite Mode in Run 1) working. However, both games still have a list of issues.
Run 3 remains on the back burner until those first two are ready.
Run 1
I’ve already released an HTML5 remake of Run 1 (which I consider to have been a beta version), but since then I rewrote most of Runaway (the underlying engine), so I’ve had to redo most of Run 1 as well. It’s coming along well so far, and since I invested in building solid foundations, fixing the remaining problems should be relatively painless.
Adventure Mode is nearly done. The levels are unchanged, but I’ve been playing around with the physics, trying to make the game feel nicer but still close enough to the original. I’ve also done my best not to mess up game balance. I know people like Run 3’s physics, but those would make Run 1 too easy.
There’s still more to do for Adventure Mode. For one thing, it saves your progress but can’t load it, so you always restart from level 1. Also, there’s no ending, and the level transitions are missing something. At the moment I’m still using the “flying through space” level transition from the beta, but it’s less interesting without all the tiles zooming into place. Either I need to recreate that animation, add other scenery to look at, or go back to the original “endless tunnel” version.
Infinite Mode is finally working! This one took a while.
I tried to adapt the original level generation code, but something went wrong along the way. The new generator makes levels that are both harder and less visually coherent. As for why it’s green, I haven’t gotten around to adding multiple colors yet.
In previous status updates, I talked about how Run 1’s Infinite Mode required an overhaul of how levels were loaded. At the time, my plan was to place the levels in 3D space, loading them as soon as two conditions were met: (1) the camera was almost close enough to see them, and (2) the player beat the previous level. The original version of Run 1 would only load a new level once the previous one was over, and it’d use the player’s performance to determine the difficulty of the next level. The more you fell, the less difficulty would increase (though it would always go up by a little).
Well, I did that. And then I did something else instead. Whoops!
Now, Infinite Mode levels load based on the camera’s position (1), without waiting for you to beat the previous level (2). The difficulty increases as you make progress, and the tiles update in real time, which I think makes for a cool effect. (Also, the difficulty decreases each time you fall.)
I like this concept, and it took a fair bit of work to make it happen, but I’m not sure I like how it feels in practice. Pros: if it generates an unfair level, things will get easier once you fall off a couple times. Cons: it feels less like you’re making progress if you can just lose it again. In the original version, any progress you made was locked in. I could go back to that, but I think (hope) this should be fixable while keeping the cool new real-time updates.
Finally for Run 1, there’s currently no Edit Mode or costumes. I’ve got a working editor in Run 2, and I should be able to import that without too much trouble. Not sure what I want to do about the costumes, though. Do I keep them as costumes, or is it worth the time to flesh them out into separate characters with unique abilities?
Run 2
For those who weren’t there, in late 2024 I rebuilt Run 2 in a series of livestreams, better than before. New UI icons, touched up levels, clearer indicators of where you can and can’t rotate gravity, higher-resolution backgrounds, and a new sci-fi font.
I’m sorry it’s taken so long to get this thing out. Many of us (me included) expected it to be out by now, but some of the remaining problems proved stubborn. At this point, I’m going to wait until I’m ready to release both remakes at once.
Here’s what was broken as of my last stream.
The player character stutters, as if updating at a low framerate. The rest of the game moves smoothly, so it’s not actually a performance issue. And Run 1, which is using the same engine, doesn’t have this issue. Still don’t know what’s up with this.
Sometimes when you deleted a cube in Edit Mode, it wouldn’t disappear, but you could fall through it. I’m happy to report that this is now fixed!
Sometimes when you added a new cube, nothing would show up but it would still be solid. Also fixed!
Often when you clicked and dragged to “paint” several cubes at once, it would place some in the wrong layer (usually one layer closer to the camera than expected). Fixed!
There’s no way to edit level properties (color, dimensions, title, etc.) other than manually editing the level data. I still haven’t done anything about this.
Though you could save levels, there was no way to load them. I’ve since added a basic text box to paste level data into, and levels do load successfully, but this promptly revealed a bunch more issues.
The UI isn’t built to deal with standalone levels like this, so the next/previous/bonus buttons do nothing and display incorrect data. They always indicate that there’s a previous level and that you haven’t beaten the current level or earned its bonus. When you do beat the level it says “press jump to continue,” but you just jump normally since there’s no next level to go to.
I didn’t program the levels to unload, so they just stay around until you quit to the main menu. This lets you load multiple levels on top of one another, though you can only interact with the most recent one.
In addition to all that, a new rendering issue popped up. If you leave a level and then navigate back to it using the pause menu, only the level’s outlines will appear. I distinctly remember having fixed this at one point, but no, it’s still here.
This looks pretty neat in some cases, so I might add official support for it later. But I can’t keep the bug itself, as some levels lack outlines, and with neither fills nor outlines they end up being fully invisible. Good luck playing those!
As if all that wasn’t enough, I recently tried building for HTML5. It starts out in outline mode, and then the scene goes completely black if you ever move left or right. You can’t complete (or fail) the level in this state, but everything comes back if you reset, so it’s not like the game crashed. I suspect the Runner’s coordinates are getting divided by zero.
What next?
I plan to fix everything mentioned above. When these games come out, I want you to be able to do everything you could do in the original. I’ll try to leave it at that, and not get distracted working on new features. Though it occurs to me as I write this that an “import save” feature would help a lot. Then you can pick up exactly where you left off.
I also want to do some marketing, to build interest. Keep an eye on this blog and my YouTube channel for updates.
I’ve recently finished overhauling this site. If you’ve noticed anything different around here, this is why. (If you haven’t, sweet! That was my goal.)
Along the way, I improved the site’s security (both front- and backend), wrote a bare-bones privacy policy, and tidied up some old posts and images. I considered big changes like switching to a more recent theme, but most of them broke something or would require extra work, and might confuse visitors. So instead, I aimed to keep it as close to the old version as possible.
(Note: I have no evidence that anyone ever exploited these vulnerabilities in the wild.)
Who?
I don’t actually know who runs cryptcheck.fr, other than that they’re French and highly opinionated. The site was recommended by a security geek on social media, and as we all know, geeks on social media are infallible.
Whether or not I felt like trusting CryptCheck, Mozilla corroborated them. Their HTTP Observatory gave me a 40/100 (D-). Thankfully, unlike CryptCheck, Mozilla provided detailed descriptions of what was wrong, why it was wrong, and how to fix it.
What and why?
I was allowing unsafe inline scripts. This meant that if someone found a way to insert text into the page, they could run a script in another visitor’s browser, potentially stealing data or directing them to a virus. (WordPress sanitizes comments, but you never know when someone will find a way to bypass that.)
I was allowing other sites to embed mine in an iframe. In theory this can be used to steal user data, though in practice, what is there to steal?
I wasn’t implementing HTTP Strict Transport Security (HSTS), meaning http://player03.com didn’t redirect to https://player03.com early enough in the connection process. It did redirect eventually, but the initial connection was done over http, which would technically be enough for someone to intercept the data and redirect users to a fake site.
How?
The easiest one to fix was iframe embedding. I opened up the root .htaccess file and added two lines. The first line sets X-Frame-Options "SAMEORIGIN", telling browsers not to let other sites embed mine. The second line sets frame-ancestors 'self', telling browsers not to let other sites embed mine. I think the difference is that the former is for old browsers and the latter is for new ones.
Next, I had to disable inline scripts. This isn’t hard to do: just delete 'unsafe-inline' from .htaccess. The trick was, I wanted my site to continue working afterwards, and some of my fancier blog posts made heavy use of inline scripts. I’d have buttons that you click, each with its own onclick="do.unique.thing()" inline script.
To fix this, I went through all my blog posts and figured out a way to replace these scripts. Turns out, while onclick="xyz" is unsafe, you can just move xyz into a .js file, and then it’s safe. The site uses HTTPS, which means all the .js files are cryptographically signed, so there’s no tampering with them during transit. I also submitted a pull request to Lime to remove inline scripts from Lime apps.
WordPress uses its own inline scripts, and I couldn’t transfer those. Instead, I manually approved them using SHA-256 hashes. These scripts will run as long as they’re completely 100% identical to the versions I approved, but even adding or removing a space would make browsers reject them. This ALSO means that I can expect parts of the site to break when WordPress updates, and I’ll need to manually re-approve it. WordPress is working on clearing out inline scripts, but not quickly.
Finally, HSTS and redirection. HSTS is easy: add a single line in .htaccess, promising to keep using HTTPS for a year. As for redirection, it’s just a couple more lines of code… that didn’t work. Each time I tried, it broke the whole site. Digging deeper, I realized these lines could not go in .htaccess, and what’s more, I didn’t have access to the correct file.
Where?
I needed access to the Apache server configuration files. However, I was on shared hosting, and being able to mess with those files would mean I could mess with other people’s websites (and they could mess with mine). Understandably it wasn’t allowed.
To do this one last little thing, I needed to move my entire website over to a whole new server, one under my control. On the plus side, it turns out that virtual private servers are cheaper than shared hosting, at least when you get the self-managed option. Pros of self-managed: I’m in full control, and no longer need to ask permission to change settings. Cons of self-managed: I’m in full control, and with great power comes great responsibility.
Since I had already spent time configuring Apache settings, I picked a LAMP stack (the A stands for Apache) over LEMP (the E stands for Nginx). My hosting provider offered a one-click install, but that didn’t work so I installed it myself. I set up firewall rules, an https redirect, restricted accounts for each service, SSH access, SELinux, and various other security measures. After briefly confusing FTPS and SFTP, I bulk-uploaded the site’s contents.
Aside: either guides have gotten better since 2014, or I’ve gotten better at following them, because everything ended up working as described. I did run into snags, but I was either able to work through them quickly enough, or I’d discover that there was a good reason it wasn’t allowed. I ended up with an aggressively basic setup, and I’m happy with that: basic means easy to verify.
When?
This Tuesday, I updated my DNS records to point to the new site.
Several things immediately broke, most notably the CSS, due to URLs still pointing to the test version of the site. My Content Security Policy (CSP) specified that scripts and styles must be loaded from 'self', not some strange alternate-dimension version of 'self' at a different web address. (It was the same thing, but browsers couldn’t verify that, so didn’t trust it.) I updated the site link in the WordPress dashboard and Apache config files, and things went back to normal.
Then I encountered another issue: my hosting provider unexpectedly restored the site’s old DNS record, in addition to the new ones. This left visitors with a 4/5 chance of getting the correct site, but a 1/5 chance of being sent to the old one, which was now broken due to the same sort of URL issues described above.
The reason this broke? Their nameservers were for shared hosting, and I wasn’t supposed to use them anymore.
So I set up my own nameserver on the VPS. Now, when you connect to my site, your browser contacts my server for instructions on how to contact my server. Seems weird, but there are several guides for exactly this, so I suppose that’s just the world we live in.
Is that all?
First off, rude, this took over a week of research and work.
Second, no, it’s not all. I have a short list of things still to do, and I’m sure there will be user-reported issues. I’ve already received one such report: apparently Run3.swf no longer works in the standalone Flash Projector. (Not sure how to debug this, sadly. If anyone has solid information on how the Flash Projector loads files, let me know!)
Note: the questions often refer to a main character (“MC”), side character (“SC”), and antagonist, but Run 3 doesn’t have clearly-defined roles like that. I handle this by picking one focus character for the month. This month, I picked the Duplicator (a.k.a. the Negotiator) as my focus character. From his perspective, the Child and Angel are the most important side characters, and the Lawyer is his overarching antagonist.
April 1: MC POV: Write a Mastodon introduction post.
Not that my setting necessarily has text-based social media, but if it did…
Hey there everyone! I’m the 🗨️Negotiator, and I hope we’ll all be good ❤️friends!
Here’s a bit about me: I’m a loving husband and father of 🎈one, living sustainably off the grid and looking for ways to make things better.
I’m recently retired, because it turns out you can’t 🔧fix a broken system from the inside. I took with me far too much secret knowledge for my own good, and I’m eager to 📣share that info with anyone and everyone who can use it. If that’s you, please get in touch ASAP because someday they will put me away!
⚠️⚠️⚠️ This post does NOT apply to you if you work for the Government. Government workers—including contractors such as Architects, ninjas, pirates, and athletes—do NOT have permission to view or interact with my social media account. ⚠️⚠️⚠️
April 2: What books/resources have you used to improve your writing? Which ones do you recommend?
I could recommend specific sources, but honestly I think those are a matter of taste. TV Tropes was a great fit for my younger self, but it isn’t right for everyone. Nowadays I get most of my advice by listening to individual writers, especially in serialized works where the author posts their thoughts on the latest entry. And even if they don’t, simply consuming media is a great way to learn more about what you like and what you don’t, if you pay attention.
Perhaps this is why I’m drawn to media by solo indie creators. Most of the time, I can figure out how it was made. If I like a part, I have enough information to try something similar myself. If I don’t like a part, I can guess why they did it and what went wrong. In big budget productions by large teams, all the rough edges are filed off and that information is gone.
April 3: Antagonist POV: How do you feel about animals?
Animals are adorable! Have you seen my puppy? You could never find another animal so smart, so well-behaved, or so handsome!
…
Excuse me? I never said that. Let me see that article!
Aha, of course. This insufferable tabloid took my words out of context, as they love to do so very often. You should really be more careful about what media you read.
But no matter; I can clear this up. I said that as part of a longer interview about commercial animal breeding. When I said that no one would love these animals, it was with great sorrow, to explain why this is wrong. All animals deserve a loving home, but when these breeders breed more animals than there are good homes, it inevitably follows that some will fail to find a home, or will be given to a bad home. Hence my call to outlaw breeders, or at least create a minimum wealth requirement for pet ownership, to ensure all pets will be cared-for the way they deserve.
For the record, he never did give that magazine back. It went straight in the recycling.
April 4: Is there writing advice you used to follow but changed your mind?
Not that I can recall. I don’t consciously follow other people’s advice while I write, which means I can’t exactly stop following it.
Like every other young writer, I was told “show, don’t tell.” Feels like that advice is everywhere.
It sounded like good advice, but I have always been a little contrary, so from the start I put a twist on it. I would tell (or have a character tell), but in the process I’d show something different. My characters often make bold statements, telling each other (and the reader) what to think, but the more important thing is how they say it or what they leave out, because that shows something about their character.
Sometimes it’s as simple as “this character will geek out if given a chance.” Other times, it hints at ulterior motives, or past events. There’s always something, not because of any rule, but because I get bored writing if there aren’t at least two things going on at once.
(I never changed my mind on this, but I think it’s relevant enough to be worth sharing.)
April 5: SC POV: Who is your favorite person to be around?
Uhhhh…. Can I say the Bunny? ‘Cause if not I’d have to pick between Dad and the Angel, ’cause there’s no one else coming with us.
…
Don’t tell him, but Dad’s no fun these days. It’s like, yes Dad, I know the Angel’s mean and bad, but can we talk about anything else?
At least the Angel shows me how to build stuff, that’s kinda fun. I tell Dad I’m doing espinage– esp-pi– espi-o-nage. It’s a word that means like I’m spying on him, except without the hiding part. But I’m not doing much espi-o-naging or much spying, I just wanna make some things. And even though he’s a big ol’ jerk, he tells me how.
Angel:
That’s easy: my friends back home.
I’ve missed our game nights, I miss listening to the Digger go on about rocks for hours on end… I guess I miss getting pranked by the Jester. He’s always coming up with cool new widgets, but of course he can’t show them off normally, he has to come up with a prank that makes you doubt reality for a second.
Most of all, I miss being around people who can check my work! Other than myself and the Runner, no one here in the Tunnels has even a basic level of competence. I’d count myself lucky there are two of us, but for some reason she’s off wasting time instead of helping get home.
The Child gets a pass because he’s young and willing to learn. He can barely hold a wrench or soldering iron, much less remember where all the parts go, but when you point out a mistake, he fixes it. That alone could make him the least-bad engineer in his generation.
April 6: Does your MC feel understood? Why/why not?
It boggles the mind how little people understand. How much they willingly accept.
Aren’t these projectors the Architects installed great? New toys to play with! Free toys! What could be wrong with free? Don’t mind the cameras, they let you control your toy, that’s all.
Let the toys distract you from our divisions. Rich and poor? That’s how it’s meant to be. Male and female? Yeah, let’s cut society in half again, and make fun of anyone who reaches out across the imaginary aisle. Hey, let’s sign up for careers! Isn’t it nice how we get to pick which box we’ll be trapped in?
Start questioning any of this and boom: pirate attack. Panic, find shelter, let yourself be distracted. Cheer in relief when ninjas “save the day.” Don’t ask where they come from, or why they’re so evenly matched.
Why can’t anyone see the pattern? Our Government is terrified of what we could do together. They want us divided, surveilled, and afraid.
April 7: What conflicts (internal and/or external, subtle or grand) are important in your story?
Can I count mysteries as a type of conflict? My story features a lot of them. Even in-universe, they’re important. The Duplicator is racing to uncover what he believes to be a massive conspiracy, and if he’s right, there are forces working to make sure no one figures it out.
Beyond that, we see plenty of characters get into arguments, there’s the challenge of getting home from outer space, and after that the end goal is for a family of three to face off against a planetary government.
Speaking of that family, the Duplicator and Demagogue are counting on their son to work with them, but he’s still figuring out what he wants to do with his life. Will he do what he thinks of as the responsible thing? Or will he follow his own interests?
They imprisoned me in outer space because I knew too much. I’m separated from my wife, and my son is separated from his mother. Everyone else trapped with us is either a liar or a fool.
It’s hard to see the bright side, some days.
But there is a bright side: we can see all the other things they locked away. Alien life, vast riches, mutagenic chemicals, and secrets of the Universe itself! If we can bring home the proof, the jig will be up. Society will see the truth and rise against the Government, and it will all have been worth it.
Here’s some background knowledge from my story, for context. No comment on how accurate his interpretations are.
“Alien life”: a tunnel assembled itself out of component pieces, and tunnels seem to have some sort of sensory apparatus.
“Vast riches”: the Tunnels have hundreds if not thousands of batteries floating around, and their society uses batteries as currency. They aren’t the same type of battery, but everyone seems to be assuming you can substitute them.
“Mutagenic chemicals”: the Duplicator ingested an unknown substance, went catatonic for multiple days, turned blue, and gained the ability to make holographic copies of himself.
“Secrets of the Universe itself”: there’s a lot of advanced technology on display, including a large wormhole in the distance. Plus, there are some phenomena that haven’t been conclusively explained.
April 9: What powers (e.g. political, religious, corporate, magical, natural, etc.) influence your characters’ lives?
Political: there’s the Government itself, plus several factions attempting to influence it. The Duplicator generally interprets these factions as either working for the Government or being their pawns.
Religious: Pastafarianism is a serious religion in this setting. Others follow the Founder, though they insist he’s real and they aren’t a cult. The Sage provides guidance to those who seek it out, but claims no religious significance.
Corporate: the Architects are a wealthy family who behave something like a corporation. They take an active role in politics and other affairs. The Factory behaves more like a non-profit, taking a passive role.
Other: the strange technology of the Tunnels shapes how the main cast gets from place to place. A lot of this technology conveniently produces platformer game mechanics. (I made the game first, then wrote the story to explain it.)
He has the power to create semitransparent copies of himself nearby. They mimic his motions, interact with the world, and don’t feel pain. If he’s in trouble he can swap places with any of them.
An ability like this would seem to be useful in a fight, but unfortunately for him, this story doesn’t feature combat. It’s considered pointless, perhaps even childish. Neither he nor his enemies would think to solve their problems that way.
Before the story began, he had been a legislator with considerable sway within the Government. He tried to serve as the voice of the common people there, always consulting with constituents and presenting their ideas and concerns to the other officials. Then one day, he willingly stepped down, giving up all that power and influence. Now he peddles wild conspiracy theories and works to bring the whole Government down.
April 11: How much power does your antagonist have?
Most of my story so far has focused on eight individuals stuck in outer space. Most of them could represent a community (conspiracy theorists, engineers, Pastafarians, rich people, athletes, scientists), but it’s hard to say that the community plays a role in the story with only one member present. Probably the best indication of this is that the story hasn’t made clear whether the characters are typical for their respective communities. Do all Pastafarians talk like that? Who knows, we’ve only met the one.
That said, I’m working to flesh out more communities. For example, artisans. They’re a loose-knit movement who make things by hand, and since the Duplicator swore not to trust anything that came out of a 3D printer, they’ve been his go-to source of goods. He always tells them to keep fighting the good fight, even though activists are in the minority. Most artisans do it as a hobby or a point of artistic pride.
April 13: What are some of the tropes typical in your genre? Do you use them?
I honestly don’t know what to call Run 3. Is it sci-fi because it’s in space and features alien characters? That feels reductive. Is it slice of life because everyone’s doing their own thing and they spend a lot of time chatting? Or is it adventure because they’re exploring?
Sci-fi tropes: no laser battles, no planets with exactly one defining feature each, yes strange alien technology.
Slice of life tropes: no love triangles, yes clashing personalities, yes improbable friends.
Adventure tropes: no inseparable band of intrepid heroes, no shared foe (except maybe the emptiness of space), yes getting stranded away from home.
These are just the broad strokes; I’m sure there are many more.
A planner for sure, except sometimes when he’s caught off-guard.
He has a background in politics, mostly the thankless and boring kind. The kind where you’re caught between several sides who all want something different, and you spend weeks ironing out details and trying to address all concerns at once, and sometimes the best possible outcome is that everyone will be equally unhappy.
Since he married the Demagogue, the two of them have spent a lot of time on plans to delegitimize and/or destabilize the Government. They’ve gathered information (got a conspiracy board and everything), worked to win allies, trained, and more.
But there are also times when the Duplicator jumps to conclusions too quickly. His excuse is he’s playing dumb to make people underestimate him, but there’s another part of him that longs to be the stereotypical genius detective, making deductions in an instant and catching bad guys the moment they make the tiniest mistake.
April 15: What would be your antagonist’s favorite movie?
Whatever it is, I haven’t watched that movie yet. It likely exists, I just don’t watch many movies.
I suspect he’d like 24, based on Jon Bois’s description of the show (mind the CW). Well, he’d like it once he got over the shock factor, and the culture shock for that matter. A lone hero who’s the only one capable of keeping the peace in a horrible world? Someone who makes impossible moral decisions but is always vindicated in the end? That’s his jam!
I think his ideal movie would be a detective/courtroom drama with similar themes. An intrepid investigator who brings down a seemingly untouchable foe (e.g., a widely-loved but corrupt CEO), using hardball tactics to peel back their layers of deception until everyone finally sees their true depravity.
You know, just yesterday I talked about how my protagonist likes to think of himself as a stereotypical genius detective. Perhaps the two of them aren’t so different after all.
Don’t worry, my antagonist won’t drop that line during the climax. Both he and my protagonist are already well aware.
They knew it, but I’m only now realizing it. I’m sitting here rereading my post and thinking, “oh of course, that’s what they saw in one another.”
April 16: If your MC hosted a talk show, what would it be about?
That’s easy, he and his wife would spread conspiracy theories.
Breaking down the ways the Government tracks you
The confiscated items being stored in the Factory
Why recycling is a scam
We staked out a Government facility for three days (you won’t believe what we found!)
Five ways the Moon influences your thoughts (number four will shock you!)
Naturally, clickbait increases over time as the show struggles to be noticed.
I’ve spent all month talking about the Duplicator’s obsession with the Government, and I’m worried it’ll get stale. So let’s suppose he can’t talk about conspiracy theories; what other shows might he host?
He likes puzzles and mysteries, so he could review the latest mystery books/movies, interspersed with puzzles for the listeners.
His family plays subversive TTRPGs, and could stream their sessions. (Not a talk show, but whatever.)
He has ties to the artisan community, so perhaps a show where they bring artisans on to talk about their latest projects.
He likes talking to people one-on-one about all sorts of things, and probably misses that part of his Government days. (Downsides to turning yourself into an outcast.) Honestly he could go for all kinds of subjects as long as he was meeting a variety of people.
April 17: What personal expertise of yours makes it into your books?
I’d hesitate to call myself an expert in anything besides programming and game design, and the story isn’t about programming or game design. But I do read up on various other topics, and that knowledge does have a way of sneaking in.
I’ve read plenty about how and why people make mistakes (I recommend “Thinking, Fast and Slow”), and I sometimes use that as a basis for character flaws.
When I was young I was a little obsessed with black holes. (I just thought they were cool.) (And I still do, but with more nuance.) Now I have a half-decent intuition for warped space, which inspired me to use a wormhole as a location of interest.
Recently I’ve been getting into urbanism, and I’m sure it’ll show up sooner or later.
There are more examples, but most of the ones coming to mind are spoilers.
To fit it into my story, I decided the Child would demonstrate a misunderstanding about the Runner’s map, and she’d use questions to guide him to the answer. (I also had some philosophical ideas to share about maps, so I got to do two things at once.)
Looking back, I think I made the scene too short. Rick Garlikov’s anecdote worked specifically because he took it slow, starting with a simplified analogy and elaborating one tiny step at a time. Whereas in my scene, the Child has to make leaps of logic, and I’m sure some of my intended meaning was lost. If I find the time, I’d like to extend the scene to make it more obvious (1) what the Child got wrong, (2) what he learned, (3) what the Socratic Method is, and (4) how to try it yourself.
April 18: Do you write primarily in the same genre you read as a child?
The more time I spend writing a character, the more bits of myself I notice in them. Generally this means I relate to main characters the most. Especially this month, since I decided to focus on the Duplicator as the MC. I’ve written a lot about him already, but not much about his antagonist, and I figured a month of writing prompts would be a good chance to fix that.
It’s definitely worth noting that my MCs antagonize each other a bunch. Early on, they (especially the Angel) were the closest things I had to antagonists. The Angel was almost the antagonist this month, since the Duplicator sees him as one. However, I’ve already used him as the antagonist in a previous month, and he doesn’t see the Duplicator as a foe.
I know you hate me and don’t want my help, but you don’t know how to get home on your own, so I’m going to help you anyway.
—The Angel to the Duplicator, or me to a bug in my room.
April 20: Do you plan out your themes or allow them to develop as you write?
I don’t usually think about themes. Perhaps if I did, it would be easier to write endings.
Thinking about it now, I would say the Duplicator’s story features themes of distrust, subterfuge, and institutional power. I did knowingly add those things to the story, but only because they followed from him being a conspiracy theorist. I wasn’t thinking of them as themes, just aiming for consistency.
Looking at this from a different angle, I sometimes write with the goal of sharing a specific idea, which can be like having a theme. For instance, I have a storyline sitting on the back burner because the core idea feels like it’s missing something. I know who will be where, roughly what they’ll do, and what the outcome will be, but I don’t feel like I know what the story’s about, and I can’t write a satisfying ending until I figure it out.
Maybe the solution is never to write endings. Maybe that’s the problem here. /s
April 21: If your MC’s main skill evaporated, would they survive the story?
But that’s not the most interesting answer, so let’s tweak the question.
Hey Dad, I’ve been thinking. You know how we’re gonna trick the Angel to get home?
Sure. What’s up?
I just, what if you didn’t have your duplicates? Wouldn’t that break the plan?
Yes, this plan relies on him not knowing what the duplicates can really do. But we could have made another plan instead, relying on something else he doesn’t know. We had time.
But what if they stop working now?
If the Angel could get rid of them, he’d have tried already. Oh! Unless he’s waiting for the last minute…But even if he did, we’d call off the launch and find another way.
…
What’s wrong?
…I don’t want to not go home.
Oh kiddo, it’s ok. Please don’t worry, we aren’t really calling off the launch. The plan is good.
I think it’s worth posting my first draft too. Here’s how he might have answered a slightly different question:
If I couldn’t tell people’s true motives, we’d be in enormous trouble.
To be fair, we are in trouble already. I got tricked and they were able to banish us to outer space. But the only reason we’re so close to getting back is I’ve been on top of my game ever since.
The Angel is quickly running out of time, and he knows it. He’s going to keep hoping to find an opening, and when he hasn’t found one by launch day, he’ll have no option but to drop the pretense and maroon us in space. And when that doesn’t work, we expose his beloved Government to the whole world.
…
You meant my duplicates? Come on, you know that’s not my main skill. Yes, the Angel doesn’t know their full potential, making them vital to our current plan, but without them we could have made a different plan. Without my intuition, we wouldn’t have a plan in the first place!
I think the second draft is closer to what would happen in canon, but it’s a shame to lose the insight into what the Duplicator thinks his “main skill” is. But there’s no reason for the Child to phrase the question as “what if you didn’t have your main skill?” when he could be specific.
April 22: What two senses are the most natural for you to include in your description?
In Earth years, the youngest would be 8-12, most would fall between 15-35, and the oldest would be at least 50, probably over 60. (I haven’t felt the need to nail down their ages, much to fans’ frustration.)
Generally I assume older characters have greater expertise and background knowledge, but only in areas where they’ve put in the work. Dropping everyone into deep space evens the playing field: neither the kids nor the adults have experience with alien technology, so they’re all (?) starting from square one.
April 24: Do you include characters from all socio-economic classes in your story?
Yes, but it rarely gets discussed. The Gentleman is the only one who makes a big deal out of it.
Part of this stems from the fact that there’s little use for money when you’re separated from society. Sure the Gentleman is able to build up a figurative dragon’s hoard, but what does he think he’s he going to do with it? No one’s selling anything.
The other part is that their society has a good social safety net, so no one grew up in what we’d consider poverty. On the Planet, being poor doesn’t mean you’re starving, or that you can’t get healthcare, or that you can’t afford a place to stay.
My wife is the most amazing woman you’ll ever meet. She’s gorgeous, driven, passionate, caring, and ten times the public speaker I ever was. We did get off on the wrong foot, but after giving each other a second chance, we clicked.
My ex was the exact opposite. He was the perfect partner at first: romantic, funny, well-meaning, and always finding cute little gifts to give. But over our parallel careers in politics, all that evaporated. The more power he got, the less he could think about anything else. Yet no matter what lows he sunk to, somehow no one ever believed anything bad about him.
Then I realized that the rest of the Government was equally corrupt, and I’d somehow never noticed. Turns out, they put chemicals in the ventilation that scramble your brain, and I was as clueless as the rest until one month when I happened to travel a lot.
I guess I was lucky in love twice. Once when I escaped, and once when I found the real deal.
April 26: In your story, who’s hiding (literally or metaphorically?)
I can’t seem to stop writing characters with secrets, so it might be easier to list who isn’t hiding.
The Skater is uncomplicated and wears his heart on his sleeve.
The Student isn’t deliberately hiding, she’s just an introvert.
The Pastafarian is quite eager to share her views and opinions.
Everyone else is deliberately (and more-or-less successfully) hiding at least one thing. Sometimes for personal reasons, other times because of some kind of obligation.
And of course, the Child is literally hiding. You can spot him in the background of certain cutscenes, practicing his ninja skills.
I wonder if this is a reflection of my own biases. As an introvert, I can’t imagine having the energy to be outgoing/cheerful all the time, so I don’t write any characters who do.
April 29: Who’s feeling shame in your story? Is it justified?
I usually avoid passing judgement on my characters, but perhaps I’ll make an exception this time.
No, I don’t think the Duplicator’s shame is justified. He entered politics with good intentions and did his best with the tools he had, even if he made mistakes along the way. He’s holding his past self to an unrealistic standard.
While I’m at it, I don’t think he should feel ashamed about taking so long to notice the mind-control gas: there was no such thing.
April 30: Does your MC have any pets? If so, what are they?
The Duplicator considers animal ownership to be cruel and coercive, the same sort of power-seeking behavior he saw all too often in the Government.
Instead, he believes you should befriend wild animals, like his son did with the Bunny. Allow the animal to come and go as it wishes, and never force it to do anything. If it chooses to hang around, then you know it genuinely likes you.
…So who has the worse take? The Duplicator, with “no one should ever own a pet,” or the Lawyer, with “pets are great but poor people can’t care for them properly”?
Recently, I stumbled across the Mastodon hashtag #WritingWonders, a series of short questions by Alina Leonova, Branwen OShea, and Amelia Kayne. It’s an excuse for writers to share fun facts about your story, and see how other writers tackled the same topics.
Note: the questions often refer to a main character (“MC”), side character, and antagonist. Run 3 doesn’t have clearly-defined roles like that, but for this month I decided to treat the Runner as the main character, the Skater as the side character, and the Angel as the antagonist.
May 1: Intro Day. Share 3 fun facts about your favorite side character.
Fact about the present: of the main cast, the Skater is the one who most enjoys the game-like nature of the Tunnels. The moment-to-moment experience of timing his jumps, sticking the perfect landing, and replaying the same level over and over to find ever more optimal routes. In other words, he’s the one most invested in the core game loop. For comparison, the Runner is more into the meta loop of exploring and completing her map, and the Angel only cares about the meta meta loop: getting out of this place.
Fact about the past: the Skater will tell you that he’s awful at STEM, though in reality, his grades were just mediocre. He just has bad memories of the class laughing when he got an answer wrong, overriding the facts of the matter.
Fact about the future: the Tunnels are merely the start. The Skater intends to become a Planet-famous gymnast, capable of turning any obstacle course into a spectacle of color and motion.
May 2: What is your favorite side character’s relationship to the MC? Do they get along?
(Clarification: I don’t actually have favorite characters, the Skater is just one who’s had a side role so far.)
The Skater and Runner get along just fine, thanks for asking. I guess they got off to a bit of a rocky start when the Skater bowled the Runner over and made her drop her map and stayed only long enough to help retrieve it before skating off. He was just very excited about this new environment. And he did stay to help!
Later on (not shown yet), they start a friendly game where each tries to “prove” the superiority of their means of locomotion, by finding a level they can cross that the other can’t. Basically it’s an excuse to hang out and practice obstacles.
From the Runner’s perspective, the Skater is one of the least stressful characters to be around. Everyone else asks tough questions, or is abrasive, or otherwise requires mental effort. The Skater only requires physical effort (usually).
May 3: What is the criminal justice system like in your world?
If you’re accused of a crime, the outcome depends largely on where (and whether) it goes to court. Some courts have a reputation for favoring businesses, others are said to be harsh to everyone, etc.
Punishments vary wildly depending on the whim of the judge. You might pay a fine, lose your job, lose your name, get banned from a city, or get something akin to an RFID implant warning people about what you did. Imprisonment is only considered for repeat offenders.
Appeals go straight to the High Court, which almost always rejects them. For those lucky(?) accepted appeals, the Lawyer makes a point to air both sides’ dirty laundry for the world to see.
If you don’t trust the courts, you can hire a mercenary (often a ninja) instead. Careful: most ninjas do their own investigation before enacting their subtle and barely-legal vigilante justice. If they decide you’re wrong, good luck tracking them down for a refund!
The character limit kept me from going into detail on some things, like what I meant by “dirty laundry.” @Ninpan commented that “The lawyer sounds like a bit of a twat,” so I figured I’d give the Lawyer a chance to explain himself.
As a representative of the High Court, I have sworn to uphold not merely the letter of the law, but the concept of justice itself. This requires the utmost transparency.
I ask you, could a jury deliver justice with only some of the facts? Could you negotiate a fair settlement if either side kept secrets?
No, you most certainly could not. Thus, all facts relevant to the case must be brought to light, including details about the character of those involved.
And yes, concluded cases must be disclosed to the public, to help them fully understand the jury’s decision. Justice requires vindication; if the public were allowed to believe the High Court had made a mistake, the case’s winner would be denied vindication.
May 4: MC POV: What is your occupation? Do you like your job? Why/why not?
Don’t get me wrong, I still enjoy cartography, but I can’t enjoy doing it as a job. Not since everyone decided to put me on a pedestal.
At last count, four people hurt themselves by trusting my maps too much. Including my own brother! I’ve added five errors to school curricula that I know of. And I upset the Pastafarian Church that one time, but we worked that out.
I love the process of map-making. The challenge of exploring and documenting things. Distilling places and concepts down into the simplest useful representation. Figuring out which details I can omit, and which ones people need to recognize the shape of the map.
I love using my own maps. The pure satisfaction of seeing how simple tasks become once I have maps for them.
I do like making other people’s lives easier. If only that didn’t come with so much risk…
(The Runner abdicated her job years ago.)
May 5: What scents and sounds can be found in your MC’s workplace?
In her very first workplace, as few sounds as possible.
Not that you can ever truly achieve silence. You can pad the walls and turn off the music, but there’s still the ticking of a clock, the hum of a ventilation fan, the scratching of a stylus, the shrrpt of a paper cutter, and so on.
There are also smells of paints and dyes, new and old books, the faintest waft of fresh air from the ventilation, and if you’re lucky, the aroma of fresh baked goods.
Near one door, you might make out the hum of a heating element or the bubbling of a chemical solution. From the crack in the door might waft the scent of acids and bases, experimental polymers, rusted metal, and more.
Sometimes, there would be the squeak of that door opening, followed by a quiet conversation lasting minutes or hours. Or rarely, a not-so-quiet argument, about topics such as if it’s appropriate to disassemble your father’s clock to make the ticking stop.
Following one such argument, the building was very nearly silent for a time. No notes being written on paper, no chemical solutions boiling, no ticking, no fan. Just one set of footfalls on soft carpet.
This silence was broken briefly, first by a girl’s voice, then by a boy’s.
“Well maybe I’ll just find somewhere else to live.”
“Could you, please? That’d benefit us both.”
This may have been followed by a grunt of frustration from the girl (having failed to get the response she wanted), but no one can prove such a thing happened.
After another, shorter, period of silence, sounds of packing began. Shifting boxes, zippers opening and closing, stacks of items falling over, and the occasional exclamation of delight at the discovery of a lost possession. Several hours later, a faint buzz and the smell of ozone trailed a vehicle leaving the premises, and silence reigned once more.
The Cartographer’s second workplace featured instrumental music and the smell of the sea.
Credit where credit is due: some of my descriptions were heavily inspired by Betsy Lee’s Calamity Observes: The Silence.
Disclaimer: fan art always involves the artist’s personal interpretations. I featured it here (with permission) because I like it, not to confirm or deny that these interpretations are canon.
May 6: If your opening scene had a theme song, what would it be?
The Runner is pretty restrained, so it’s rare to hear more than a sensible chuckle from her.
There are a small number of things that can make her totally break down laughing, and it’s never the sort of thing that you (or she) would expect. When it happens, it comes out as a kind of wheezing guffaw, generally accompanied by a few gasped-out words, an attempt to get herself under control, and then at least one relapse.
She finds this totally embarrassing, and tries not to let it happen.
May 9: MC POV: When was the last time you laughed? Why?
The other day the Student and I spent a while hanging out, and she asked if I thought humans could really exist.
If you haven’t heard of humans, they come from these old pop sci-fi stories, which describe them as tall, hairy, reddish-brown aliens. Usually with a bunch more strange traits and abilities.
So I said yeah, almost anything could exist, as long as you leave out the blatantly supernatural stuff. Super strength and speed could come from advanced biology. Future vision and water breathing, probably not.
When I mentioned these examples, the Student immediately pulled up a story on her e-reader. Apparently, not only does the protagonist use some kind of precognition for danger, not only do they dive into a lake for protection, they claim their body contains over 50% water. So the two of us shared a laugh at the absurdity of the writing.
…Hey, if you specifically wanted a joke, you should have said so.
May 10: How much humor is there in your story? Share a funny snippet if you want!
I never focus on writing jokes. Sometimes I have a silly idea and decide to write it in, but rarely as just a joke. There always has to be some character development or plot progression or something, so that if other people don’t find it as amusing as I do, they can still enjoy the story.
Beyond that, I think this ties back to the lack of confidence I mentioned in my earlier writing.
For instance, early in the story, the Duplicator accuses the Runner of stealing a planet. I think this is a funny concept, but instead of exploring it, I had the Runner shut the idea down.
Maybe it’s still a funny scene, but less so than I think it could be. Also a bit out of character for the Runner. Nowadays she never passes up a teaching opportunity.
As an experiment, I want to try rewriting the scene.
Hey! Runner!
Bad news: our planet is missing! It’s gone, like *poof*!
Oh, uh, yeah.
Just “yeah”? [narrows eye] Did you already know about this?
It left us behind the moment we landed. You didn’t watch it go?
I watched- uh, never mind that.
What do you mean it left us behind? Planets don’t just leave!
Hear me out. [pulls out map]
The Planet orbits quite a bit faster than these tunnels, putting it somewhere ahead of us, in this range. [drags the image of the Planet back and forth]
Hmm, I see. Wait, how are you moving the Planet?
[gasps dramatically] It was you! You stole our planet using that map!
Beg pardon?
How could you, you fiend! My wife lives there!
Hah, I wish maps could do that.
…No I don’t.
Is it funny now? I don’t know, but I do prefer it to the old version:
Duplicator: The Planet is gone!
So? It’ll come back.
How do you know? *gasp* It was you! It was you! You stole the Planet! That’s how you know!
…
I think I’ll ignore that entirely. Now help me map out this next area.
[time passes]
So… Where’d you put the Planet? I promise not to tell.
You still think I “stole” it? Think. Why else might a planet move?
I’m going to find another tunnel to map out. Catch up once you realize the Planet orbits faster than us.
I know brevity is the soul of wit, but I think that version did a disservice to both characters by not giving either of them a chance to explain themselves.
May 11: Does your MC laugh or cry more in the story?
I’ve talked before about how I designed the game first and wrote the story around it. And the game is a straightforward (pun intended) platforming challenge. One of the most common questions before I started writing the story was “what are the character running from?” Since I was feeling contrary, I decided the answer was nothing: they were running to something, and weren’t in danger.
This led to a story that… well, it isn’t lighthearted exactly, but it certainly isn’t dark. It’s just a story about a group of aliens exploring a very strange location. No time to be sad*, there are mysteries to solve!
*Not true, there’s almost nothing but time. And while some of the others might be going through some stuff, the Runner is enjoying the break from the hustle and bustle.
May 12: Do you think your story will make your readers cry at some point?
There are sad scenes that I could write, yes. Some characters have sad/difficult backstories, for instance. The question is, will the story ever call for exploring those events? I intentionally haven’t decided yet.
I’ve found I enjoy writing most when I’m not 100% sure where it’ll end up. Which might be why it’s so hard for me to finish the plot: I already planned out events that will happen, so I find those scenes less fun to work on.
Besides that, I inadvertently ended up with a lot of children in my audience, and I have to keep them in mind. I’m still going to write what I want, but I also have to be careful how I present that writing.
As an example, if part of the story featured animal abuse, that might not make it into the main game. I might instead release it as a spinoff story with appropriate warnings.
May 13: Share a description of a secondary character.
Run 3 isn’t exactly a written work, but if it was, this would be the Skater’s first chronological appearance:
The inside of the square blue tunnel was silent by the time the Runner touched down. It appeared everyone had already left.
No, check that. An adolescent sat alone in the corner, his arms full of broken red and white items, and a look of intense concentration on his face. His athletic build and sun-bleached skin suggested a great deal of time spent outdoors.
The boy grumbled in frustration as he attempted to shove a dented wheel into what looked like the bottom of a boot.
“I can hold something for you,” the Runner offered.
“I saa, I gah hiss,” he retorted, trying not to drop the additional pieces held in his mouth. He tossed the wheel into the air, flipped the boot over for a better angle, then deftly re-caught it.
The Runner decided to leave him to it for the moment.
The Skater is next seen doing this:
May 14: MC POV: Have you ever broken anyone’s heart?
Oh absolutely. Celebrities get lots of attention, but we can’t possibly date everyone who asks, much less commit to long-term relationships. I’ve lost count of the number of people I’ve had to turn down.
You’d think by now I’d know a good strategy to turn someone down, but nope. Everyone takes it differently. If you give a reason, some people take it as a challenge: fix this thing and try again. If you give no reason, some people take that as an invitation to keep trying.
Stepping back from the public eye helped a lot, but it still happens. I mean, consider this. Of the seven people here, three either asked me out or mentioned having feelings for me.
Oh don’t worry, I got used to it long ago. Feelings happen.
For context:
The Runner is too polite to name names, so I guess I’ll just have to post this here instead.
Angel: / (asked out, mentioned feelings)
Gentleman: (asked out, likely for political reasons)
Student: (mentioned feelings)
May 15: Is your MC good at romantic relationships?
She spent a large portion of her life as a celebrity, and it takes time to relearn how to talk to people as equals. Fortunately, the Sailor has plenty of good advice on the topic. Unfortunately, theory is not practice.
I guess it could be telling that she’s in no rush to head back home. If she’d made close friends back home, wouldn’t her priority be to get back to them?
(The answer is no. Friends can wait; there’s advanced technology to discover and a galaxy to explore!)
But it’s also true that she’s made closer friendships out here than she had back home. This is partially a consequence of being stuck with only a few people to talk to, and partially thanks to having more practice.
May 17: Secondary character POV: do you trust the MC? Why / why not?
Stole the- Are you kidding?! She didn’t steal the Planet! That’s the stupidest thing I’ve ever heard, and I say some pretty stupid things, let me tell you.
Nope, she never tried to take my stuff. Your son did, though. Yes, I can tell.
…Are we done here? Can I be excused?
What’s wrong with going where she says? She has the map, I like exploring.
Why would she set a trap? How would she set a trap?
Hah! I could get out of that easy. That’s barely even a trap.
Yeah well, I guess I’m just awesome then.
Enough, ok? She’s not like that, and I got stuff to do. Bye!
No I don’t know who she was talking to. Maybe she was thinking out loud. Who even cares?
Yeah no way, that’s not her style. I’m leaving now, ok? Ok.
…Do you mind?
…Uh huh.
…Oh. I guess?
Fine, jeez, I’ll ask her about the Government! Bye.
Astute readers will have noticed that the Skater didn’t exactly go into detail. Part of that was the fact that his unnamed conversation partner was being antagonistic, but there’s at least one reason that he’s just not going to admit out loud.
A big reason he trusts the Runner so much is he used to smuggle her maps into exams to cheat. They always provided good answers in an easy-to-understand format, so he came to rely on them. And, dare I say it, trust them. So by extension, he trusts the person behind the maps.
Yep. Especially back in the day, when she was on top of her game as the Cartographer. She had poise, confidence, energy, and a rotation of fancy outfits. This all fueled the hype surrounding her, and the hype in turn drove her to refine her performances. (Like how some real-world video essayists turn each essay into a small theatrical performance, complete with costumes and sets.)
She had a lot of fans, and when you have a lot of fans, some of them are likely to be *~admirers~*.
In her mind, it was all meant to educate and inspire people. Showmanship helped emphasize important points. Printing maps/diagrams on her outfits could pique people’s curiosity in new subjects (at the expense of temporarily staining her skin underneath). Maintaining a large following meant there would be a whole community willing to put effort into learning from her.
May 19: If they knew who you were, would your MC save your life?
But she’d have some choice words for me afterwards, and she’d demand concessions in exchange. She even has a way to hold me to it: she’s keeping secrets that would mess up the plot if revealed.
Fortunately for the plot, this scenario seems unlikely to happen.
May 20: Do illicit substances play any role in your story?
Well, I could say “find a better work-life balance.” That would’ve saved past me a fair bit of grief.
But you know, I pulled through, and even learned from it. If I only get to send one message, do I really want to spend it on undoing that?
Instead, what if I sent advance warning of a disaster? “On Calming 35, double-check the coupling between cars 26 and 27 of the City Circuit Train.” That single tip would have saved hundreds of person-hours of cleanup.
No, even better: “Tell the Factory workers to scan for ozone pockets before rerouting any rivers.” Or I could sound the alarm about the raid that destroyed the First City.
Sorry, I have a habit of turning personal questions into optimization problems. Given actual time travel, I’d try to save the First City, but if that doesn’t fit the spirit of the game, then I’ll go with avoiding burnout.
This was the longest I’ve spent on any #WritingWonders question, specifically because the Runner needed to mention a date, and I had never spent the time to nail down a calendar system.
Several hours later, I finally have one, complete with number of days/weeks/months in a year and day/month names. The first part was tricky because math, the second was tricky because names.
(Fingers crossed that I did enough research, and I didn’t get Calming and Weathering backwards…) 2024 update: I definitely got some things wrong. My new tentative list is Calming, March, Buildup, Weathering, Trek, Foundation, and Deluge.
May 22: Do you prefer writing the first or last chapters?
I was going to say “first,” but then I realized the answer is probably “neither.”
Most of my plots start in medias res, skipping the scene-setting and exposition. Also, zero out of three major plotlines have an ending written yet.
In other words: what happened before a scene is a secret, and what happens afterwards is also a secret. Or sometimes it’s a puzzle rather than a secret, something you can figure out if you pay attention to the right details. I enjoy writing bite-size mysteries; not much else to it.
May 23: If you switched places with the MC, would you survive the story?
Depends if I could get a farm going before running out of rations my body is capable of digesting. I’ve previously stated that such rations exist, but I don’t know how many there would realistically be.
Thing is, I barely know anything about farming, and I know even less about hydroponics. There might be a guide somewhere, if I could find it among all the odds and ends. Even then, I’d say my chances are slim.
This despite everyone else being (more or less) friendly towards me. Friendly and not in any danger themselves, but they’d have to watch the first alien they ever met slowly dehydrate and/or starve. (“Care and feeding of alien beings” was sadly not part of their school curriculum.)
…
Wait a minute, I know all the spoilers. There is a way I could cheat the system and almost assuredly survive, though it wouldn’t be particularly fun.
May 24: Secondary character POV: What was the best thing the MC has done for you?
Yes he does, but beyond that I think I have to pass on this one, sorry. I haven’t done enough research and I haven’t nailed down enough details about their metabolism.
Like, I could say he’s a fan of spicy foods, but I couldn’t tell you what chemicals or substances make food taste spicy to them. (Because it isn’t necessarily capsaicin.)
May 26: Does the media or public opinion play a role in your story?
Not at the moment. At least, not directly. The cast is on their own, far away from the media and the public.
That said, several of the characters are driven by hopes of becoming popular, changing public opinion, or righting wrongs. (Almost typed “writing wrongs.” No, that’s my job.) So though society is far away, it indirectly plays a role.
Here are the characters most concerned with the media and/or public opinion:
The Runner’s biggest question in this story is “what lies beyond the Wormhole?” Her second-biggest question is “should the public find out about it?” After all, someone went to some lengths to keep it secret.
The Skater wants to be a famous athlete. He sees this as a chance to catch up to the competition, by practicing on obstacle courses they don’t have access to yet.
The Duplicator wants to shine a light on the Government’s wrongdoings. He sees this as the biggest Government cover-up ever.
The Gentleman is almost completely driven by the idea that success is the best revenge. He sees this as a unique opportunity to accrue wealth, influence, and incredible technology.
May 27: What genre of music best fits your current WIP?
The game’s soundtrack, written about a decade ago, is full of high-intensity techno*. It fits the action gameplay quite nicely, but the story has started to go a different direction. Nowadays I write more about learning, searching, interpersonal conflicts, secret-keeping, self-doubt… All kinds of things besides action.
*Or something electronic, at least. I can’t always tell the difference between these genres.
If I were to expand the soundtrack, I’d still want electronic music for consistency, but I’d want a wider range of moods.
May 28: Secondary character POV: What was the worst thing the MC has done to you?
Trying to parent us. Like, what’s even the point of running away from home if all the adults are gonna keep telling us to eat healthy, go to sleep, and play nice?
What if I DO want to be like the kids in the stories? What then? Besides, fairy tales aren’t scientific. There’s no such thing as “turning into strong wild garbage” or “going to the Never Land where you can never grow up.” They made it all up to scare you, and I’m not fooled.
…So yeah, that’s about the worst thing I can think of to say about the Runner. That she and the other adults look out for me.
The Runner isn’t even the one who brings up the stories. She brings up actual scientific reasons to do things. Stuff like the Circadian Cycle. I just wish she wouldn’t try so hard to explain it to me. She should know I’m just going to zone out!
The Government is an institution that records, interprets, and enforces the definitions of words. These codified definitions are known as “laws.” The Government’s various branches each have an official definition of what they are and what they do.
For instance, the Courts are defined as enacting justice, and since that’s in its definition, that’s its mandate. Additionally, the definition of “court” spells out how a court case is handled, mentioning the judge, jury, procedures, etc. And each of those things have their own definitions, and so on.
Similarly, the definition of each public office includes a mechanism for electing or appointing officials, and the definition of “law” includes mechanisms for creating and updating laws.
Since the Government is defined as enforcing definitions, it does so. The end result is something like a representative democracy, except with a bunch of extra steps.
Law enforcement is defined as keeping track of the official definitions of words and resolving definitional disputes. Law enforcement, naturally, tends to attract people passionate about language and linguistics. This passion gives them a reputation for being willing to fight you (and each other (especially each other)) over definitions. Academics, am I right?
Additionally, they issue regular reports on the changing use of language. The Government uses these reports to help determine if and when legal definitions are out of sync with common usage, and therefore ought to be updated.
Note that most crimes count as “definitional disputes.” For instance, if you own a piece of property, that item’s official name reflects the fact that it belongs to you. Thus, theft counts as disputing the item’s definition, so by default law enforcement will give it back to you, unless the thief can disprove the definition.
Oh, speaking of which, names are definitions too. That’s why the Government is so picky about names, and why you have to prove to them that your name accurately describes you. Your name is effectively a small law unto itself, and they take that seriously.
Fortunately, it (supposedly) isn’t that hard to change names. Just complete the name change form and the subsequent verification/renaming process. Unfortunately for anyone in a hurry, it isn’t just a name change form. A better term might be identity change form, since it’s full of questions about gender, profession, identifying item(s), and more. All of this data then becomes the Government’s official definition of you, and people you meet will be able to intuit that it’s accurate.
(For those keeping count, stealing someone’s identifying item is two crimes. One for violating the definition of the item as belonging to the person, and another for violating the definition of the person as possessing the item.)
May 30: What colors do you associate with your WIP? Why?
Mostly, none. The story frequently shifts between locations, and each location has a different color.
I do associate colors with characters, though. Brown for the Runner’s map, red for the Student’s backpack, green for the Child’s balloon, yellow for the Angel’s halo ring, etc.
I do associate red with the plot thread involving the Student, because the location is red and so is her backpack.
May 31: Does anyone that your antagonist trusts try to rein them in?
Does anyone the Angel trusts try to rein him in? Rarely, if ever.
His friends all egg each other on, challenging each other to accomplish ever-greater pranks and feats of engineering (in the vein of MIT “hacks”).
Meanwhile his mentor is very busy, and would only step in in extreme cases. I guess the Angel reins himself in to avoid his mentor’s ire, but that’s mostly “stay on the media’s good side and don’t break anything important,” not “treat people with kindness and respect.”
Lately, I’ve been thinking: I find a lot of cool media online, and almost never share or promote it even though I have a platform. So let’s fix that!
Each post in this series will start with a quick summary to convince you to go look at the thing for yourself, and then I’ll dive in and overanalyze it. (Don’t worry, spoilers will be marked ahead of time.)
Space Station Weird
Space Station Weird is Luke Humphris’s big project over the past year. Set at some nebulous point in the future, it stars a “fridge dude” tasked with maintaining a seemingly-empty space station.
At the time of this writing, there are three episodes, totaling about seven minutes long. Check them out!
Space Station Weird doesn’t have intense action or laugh-out-loud punchlines. Instead, it thrives on mystery, worldbuilding, and understatement. And there’s a quiet sort of humor in the way the narrator sounds so bored as he describes such weird concepts.
I also like the fact that it’s done by one single person. It feels like something I theoretically could make, if I spent enough time practicing that art style, not to mention sound design, animating, and voice acting. The fact that it’s (almost) within the realm of my abilities makes it more impressive to me, since I can tell how it was done and how much effort that would take.
Whereas in the case of [insert big-budget movie/game], everything is polished so well that I can’t tell how they did it or how much effort it took per person, which makes it feel less impressive. Is that just me?
Analysis
Now that you’ve had a chance to see it for yourself, here are some of my ideas about the story. Light spoilers ahead, but I’ll avoid specifics.
Horror?
With only a few small tweaks, this could be a horror story. Being stranded alone in deep space is the perfect opportunity for horror. (We know this because it’s been done so many times.)
But in this case, we get this totally blasé fridge dude, who spends more time commenting on the station’s architecture than he does on genuinely worrying information. That isn’t to say he’s ignorant of danger, he’s just very calm about it. (With one exception so far.) And since the narrator is calm, the viewer gets to be calm too. Considering the title, that’s clearly intended: we aren’t watching “Space Station Existential Dread,” we aren’t watching “Space Station Eldritch Abominations from Beyond the Cosmos,” we’re just watching “Space Station Weird.”
It certainly could become a full-on horror story in the future, but I doubt it. I think it’s good at being a sci-fi slice of life, and will continue in that vein.
Speaking of which, sci-fi isn’t specifically about the future, or outer space; it’s about possibility. Sci-fi asks, what could happen if X was true? X can be “it’s the future in space with fancy gadgets,” but that isn’t necessary. And if that’s the only change, you get a relatively boring story.
On the other hand, Frankenstein is often described as a foundational work of science fiction despite being set on Earth in the modern day. It only had one major difference: scientists could (re)create life. (And promptly neglected and shunned said newly-created life.) Exploring this possibility is what makes it sci-fi, at least according to this one definition.
And I think Space Station Weird will fall under this definition too. It won’t be a story about Fridge Dude escaping alive (horror), or killing aliens in self-defense (action), but rather learning to coexist with whatever lurks here. You know, before it kills him. That’s totally different.
Luke Humphris’s prior works
Space Station Weird is still quite short, but it follows up on several concepts from Luke’s prior work, so let’s take a moment to look at that and see what we can learn. Or skip ahead to the next section, I can’t stop you.
My first exposure to Luke Humphris was while he was writing Dumb Drunk Australian, a long-form autobiographical webcomic. I stumbled upon it towards the end, but upon re-reading, it gets really dark at times. You’ve been warned.
Stories talking about my experiences with Australian drinking culture and toxic masculinity as well as feelings of not belonging.
I think the comic caught my attention because I liked seeing him explain things with silly faces.
The things being explained weren’t always fun…
CW: alcohol
…But Luke knows how to turn bad times into good anecdotes. Sometimes all it takes is a calm reaction to a bad situation, or a completely blank-faced reaction to a weird situation.
CW: alcohol
So yeah, his writing style and sense of humor were there all along.
Dumb Drunk Australian ends rather suddenly. Maybe some pages got lost, but it was going to have to end at some point. The comic was supposed to be about looking back with the benefit of hindsight, not chronicling his life in real time.
Instead, he made a new comic to chronicle his life in real time. My Body is a Bad Robot tells us about his daily life as he struggles to quit drinking. It’s… more positive on average than DDA, but still has some very dark moments.
On the other hand, it includes this extremely normal picture of him questioning his sexuality.
I said earlier I don’t think Space Station Weird is going to turn into straight-up horror. A big part of that is because Luke spent so much time developing his offbeat, understated brand of humor, and I’m hoping he keeps playing to this strength.
Space and time
In Bad Robot, Luke occasionally mentions that he’s spent a lot of time thinking about space.
It’s rude to try to psychoanalyze an author you’ve never met, but what if they psychoanalyze themself and you quote them? Is it ok then? (I sure hope so!)
Running from problems is a recurring theme in Luke’s comics. In DDA, Luke literally runs away from a faceless character labeled “problems.” More than once. And in one of the two (I forget which), he briefly fantasizes about going into a coma until everything is better.
Is this what Space Station Weird is about? Is Fridge Dude running from problems, spending all his time asleep so he can skip ahead to some future utopia? Is he traveling to space just to be away from the world?
I don’t think so. It isn’t foreshadowed, nor does he mention it. Fridge Dude isn’t running from anything, he’s just already disconnected from reality. The world isn’t progressing towards utopia as far as he can tell (though he mentions that other fridge dudes think so). He didn’t even choose to go to space; a powerful corporation assigned him there.
If Luke’s writing process is anything like mine, I’d guess that these are all recycled ideas. For instance, after spending some time thinking about the coma concept, you might realize the problems with it. Whether or not the world got better, you’d be too alienated to tell. Not something worth putting yourself through, but potentially something worth putting a fictional character through.
Exploring the possibility further, you might start to flesh out the character’s personality: aloof, skilled but maybe not up-to-date, with hobbies that allow for long breaks. If you’re simultaneously developing an interest in space, it wouldn’t take long to realize ways that it complements the character: physical distance as a metaphor for emotional distance, plenty of machinery that needs to be repaired by someone who knows how old tech works.
A lot can go wrong on a space station (don’t tap the glass!), and you might write those down to use as plot points. Then perhaps you spend a day sketching fun zero-G room designs, and in the process you happen to think of a reason a space station might have been built with all these different styles. Suddenly you have a backstory for the station! By following ideas and seeing what their consequences might be, you can turn vague daydreams into a detailed setting and plot outline. (Now just add small details to finish up.)
I don’t know if this is really how it went down, but it could have been. At the very least, think of these last four paragraphs as a glimpse into my own writing process.
The weird messages
Unmarked spoiler warning from here on out. This is your last chance to watch the videos for yourself.
Episode 0 is mainly scene setting, which might be why it’s number 0. Episode 1 is the first time we get a good look at the station and start getting hints about the plot.
– The station is built in a ton of mismatched styles. At least one of these areas still uses an ancient Windows computer.
– Fridge Dude was woken up to work on life support systems, systems that wouldn’t be needed if he wasn’t awake.
– There’s no timeline for when he gets to go home.
– Fridge Dude’s bunk has a frankly ridiculous number of scary messages scrawled above it, plus a bloody handprint and what might be a claw mark. Or as Fridge Dude describes them, “a few weird messages.”
What do these clues point towards? Is it all one big mystery or multiple smaller ones?
I think the most straightforward explanation would be the horror one. There’s a monster on board, one that requires oxygen and occasionally eats people. Each previous group built a different section of the station in a different style, then scratched a message or two into the bunk before the monster killed them, leaving them unable to update their computer software. Fridge Dude is merely the latest sacrifice, and isn’t meant to make it home. Why? Who knows.
Possibly the weirdest explanation I can think of is that all the machines gained sentience somehow. Phil asked Fridge Dude to repair the oxygen machine for the oxygen machine’s benefit, not Fridge Dude’s. That could also explain what Phil means by “family” and “we love each other.” And why a spacesuit is walking around on its own. This doesn’t explain the weird messages, or why Fridge Dude was penalized for losing the suit, but perhaps there are multiple separate mysteries afoot.
Speaking of which, I suspect the weird messages might not be literal. As Monty Python points out, if someone was dying they wouldn’t bother to carve “aaarrgghh,” they’d just say it. Would a dozen different murder-victims-to-be all take the time to carve their last words into the same spot? Seems unlikely if you think about it. I’ve thought of one reasonable alternative so far: maybe someone carved the messages there as a trick. For whatever reason they wanted to make Fridge Dude think people died, and went overboard with the number of messages.
Conclusion and episode 3
A lot of mysteries remain in the weird world of Space Station Weird. Which is good, because IMO that’s one of its biggest appeals. That and the humor.
Episode 3 is what prompted me to finish writing this post, which I made sure to do before watching it, so I wouldn’t spoil anything that isn’t already public. But I can at least make predictions! If trends continue, this episode will contain one new non-human character, a small number of answers, a large number of questions, and at least one moment where Fridge Dude has a calm reaction to something ridiculous and/or terrifying. Oh, and Luke mentioned that he pushed his limits on some scenes, so expect cool visuals too.
When it comes out, I’ll try to resist the urge to come back here and delete/replace all my wrong guesses. But no promises!
It’s been a while since I last posted, but don’t worry, I’ve been keeping busy.
Last time, I talked about spending the first half of 2022 working on Lime. Since then, most of my changes were categorized and merged. Small bug fixes are to be released in v8.0.1, while everything that counts as a new feature will come out later in v8.1.0. Except for the two huge changes that I spent 4+ months on; those have to wait for v8.2.0 because we want more time to test them.
I spent most of the second half of 2022 on my own projects, gradually working my way up through the layers Run is built on.
Over the summer, I rewrote and documented practically the whole codebase. I fixed bugs, cleaned up the unit tests, added new features like better timekeeping, wrote lots of documentation, and generally improved maintainability. But I never lost sight of my goal, which was to get back to work on Runaway. I only added features that I knew I’d need immediately, rather than trying to plan ahead too far.
Runaway
Between August and October, I split my time between Echoes and Runaway, gradually shifting towards the latter but going back to Echoes whenever I found a new bug or needed a new feature. And the first part of Runaway I rewrote was the math. Math is fundamental to games, and it’s worth doing right.
Here, MotionSystem performs two basic operations. First it uses Acceleration to update Velocity, then it uses Velocity to update Position. Because this code gets run every frame, it produces the appearance of 3D motion.
To keep things simple for that post, I handled x, y, and z on separate lines. However, you really shouldn’t have to do that. Any decent math library will provide a more concise option. Before August, that was this:
class MotionSystem extends System {
@:update private function accelerate(acceleration:Acceleration, velocity:Velocity, time:Float):Void {
Point3Utils.addProductOf(velocity, acceleration, time, velocity);
}
@:update private function move(velocity:Velocity, position:Position, time:Float):Void {
Point3Utils.addProductOf(position, velocity, time, position);
}
}
Convenient! I know typing out Point3Utils.addProductOf() every time could get annoying, but it still beats OpenFL’s Vector3D class:
var scaledAcceleration:Vector3D = acceleration.clone();
scaledAcceleration.scaleBy(time);
velocity.incrementBy(scaledAcceleration);
Not only is Vector3D less convenient, you have to make a temporary object. For one object that’s fine, but video games can do hundreds if not thousands of these operations per second, and all of those temporary objects have to be garbage collected.
It’s at least possible to make Vector3D more convenient. Just add a “scaledBy()” function that calls clone() and then scaleBy(), combining lines 1 and 2 above. It still has the garbage collection problem, but at least the code looks neater:
But wait! It turns out you can avoid the garbage collection problem too, using inline constructors.
If we inline Vector3D’s constructor and functions, then the Haxe compiler will copy all that code into our function call. After moving the code, the compiler will be able tell that the clone is temporary, and doesn’t actually need to be allocated. Instead, the compiler can allocate local x, y, and z variables, which incur no garbage collection at all. Sadly, pretty much none of Vector3D is inlined (either for backwards compatibility reasons or because this isn’t a priority for OpenFL).
So I looked elsewhere. As luck would have it, the hxmath library provides a fully-inline Vector3 type. Not only does this solve the garbage collection issue, hxmath’s Vector3 offers a lot more features than OpenFL’s Vector3D. (IMO, hxmath is the best math library on Haxelib. Not that there’s much competition.) In particular, it allows you to use operators wherever such operators make sense:
class MotionSystem extends System {
@:update private function accelerate(acceleration:Acceleration, velocity:Velocity, time:Float):Void {
velocity += acceleration * time;
}
@:update private function move(velocity:Velocity, position:Position, time:Float):Void {
position += velocity * time;
}
}
(As of this writing, the += operator isn’t available on Haxelib. But it should come out in the next release.)
I initially planned to join forces, submitting improvements to hxmath rather than creating yet another math library. I submitted fixes for the bugs I found, but as I looked closer I started to find more and more things I’d do differently, as well as a couple inconsistencies. Anyone already using hxmath wouldn’t like sudden changes to function names or the order of a matrix’s elements. Breaking changes are always a hard sell, and I’d need to make a lot of them before I could use hxmath for Runaway.
So I began working on my own math library (working name “RunawayMath”), using the knowledge of macros I gained from working on Echoes. Specifically, I wrote macros to handle the repetitive parts. For instance, my Vector3 class can do in 13 lines what hxmath does in ~55.
@:elementWiseOp(A + B) @:inPlace(add)
private inline function sum(other:Vector3):Vector3;
@:elementWiseOp(A - B) @:inPlace(subtract)
private inline function difference(other:Vector3):Vector3;
@:elementWiseOp(A * B) @:commutative @:inPlace(multiply)
private inline function product(other:Vector3):Vector3;
@:elementWiseOp(A * B) @:commutative @:inPlace(multiplyF)
private inline function productF(scalar:Float):Vector3;
@:elementWiseOp(A / B) @:inPlace(divide)
private inline function quotient(other:Vector3):Vector3;
@:elementWiseOp(A / B) @:inPlace(divideF)
private inline function quotientF(scalar:Float):Vector3;
@:elementWiseOp(-A) private inline function inverse():Vector3;
@:elementWiseOp(A + B) tells the macro that when you type vectorA + vectorB, it should make a new vector with the sum of their elements (vectorA.x + vectorB.x, vectorA.y + vectorB.y, and vectorA.z + vectorB.z). @:inPlace tells the macro to enable the corresponding assign operator (+= and so on).
With macros in place, I was able to quickly churn out data types. First I re-implemented most of hxmath’s types, like vectors, lines, and quaternions (but skipped matrices because I don’t need them yet). Then, I added brand new ones, including spheres, planes, orthonormal bases, bivectors, and Bézier curves. At some nebulous point in the future, I plan to implement matrices and rotors.
I made sure to write unit tests as I went, something I’d never bothered with before. As a result, I’m confident that these new types will be less buggy than my old code. Notably, Run 1’s beta lacks shadows due to some sort of error in either my raycast code or my quaternion code. I never managed to find the issue, but I bet my new code will fix it without even trying.
I could go on about all the new features, but I really should save that for some other post.
Practical applications
By November, I was ready to start making use of all this mathematical awesomeness, by returning to the fundamentals of any platformer: running and jumping.
Well, running specifically. It’s the name of the game, after all!
Side-to-side movement
It isn’t really a secret that Run 1’s HTML5 beta looks and feels different from the Flash version, and part of that is the way the Runner moves side-to-side.
The old formula for acceleration (in Flash) used the slow Math.pow() function to produce a specific feeling. When I used a totally different function in HTML5, it produced a different feeling. I did that because I figured that if Run 3 didn’t need Math.pow(), Run 1 didn’t either. Problem was, I wasn’t very careful writing the new formula.
Now back to November 2022. This time, I wanted to try a suggestion I read in an article or social media comment. The idea is to graph speed vs. time, letting you see (and edit) how fast the player character accelerates.
The simplest case is constant acceleration. You gain the same speed every frame (until you reach the maximum), producing a straight line on the graph.
But that’s restrictive, so what about curved acceleration? Specifically, how about using those Bézier curves I mentioned above? It’s easy to get acceleration from a curve that represents velocity, and it lets me play around with a lot of options to see how they all feel.
And that’s without even changing the top speed or acceleration duration. I meant it when I said a lot of options. (Click to view.)
Out of all those options, I think the ones with high initial acceleration (convex shapes) feel the most natural.
The initial burst makes the controls feel more responsive, and then they gently approach the top speed so there’s no sudden jerk. Not only that, it’s true to life: as someone picks up speed in real life, air resistance gets stronger and they accelerate slower.
That said, the curves I showed above are extreme examples. Usually I aim for a bit less acceleration at first and leave a bit of jerk at the end. That way, it’s more obvious that you’re continuing to gain speed over time.
I don’t know which of these most closely matches the original Run 1, but I plan to find out.
Other basic components
By the way, my colorful-square demo app is more than just a rolling simulator. It’s actually a small platformer demo, with collisions and jumping and all that. Just… without any actual platforms, yet.
The “Mobility” button brings up the acceleration graph I’ve already shown. The “Jump” button lets you control how high each type of jump goes (or to disable specific types such as midair jumps). “Air” lets you tweak air resistance and wind speed.
But that’s far from all the components that went into this app. I also took the chance to rewrite and test each of the following:
Collisions, both for the invisible walls around the edges and for the boost pads in the middle. Solid collisions are automatically classified as “ground,” “wall,” or “ceiling,” making it easy to write ground-specific or wall-specific behavior. Like the walljump seen above.
Friction, including friction with moving platforms. A moving platform will pull you along with it (unless it’s icy), and you’ll keep that momentum if you jump. (I expect to use this for conveyors in Run 3.)
A brand new Orientation class that replaces the coordinate space approach I used to use. Turns out I was making things unnecessarily hard for myself, rotating the character’s coordinates rather than rotating the effects of the left/right/jump buttons.
How long can player_03 keep stalling?
As of this moment, I’m running dangerously low on things to do before I get back to work on Run 1. I’ve been putting that offworking hard on underlying projects since… summer 2021? It’s certainly taken a while, but soon I’ll be done stallingpreparing.
When Infinite Mode didn’t work, I could have looked for an easy workaround. Instead, I rewrote all loading code.
When I realized loading is best done using threads, I could have just used the tools that existed. Instead, I spent several months revising Lime’s threading classes and adding HTML5 support.
I made a decent-size demo project just to show off the new thread code. That took at least a month on its own, and I have no immediate plans for it, but at least it made pretty patterns.
I spent months cleaning up Lime’s submodule projects instead of leaving well enough alone. Now, I know more about this section of the code than almost anyone else, so I’m the one responsible for any new bugs that come up. Fortunately there haven’t been too many.
I spent over a month (hard to measure because it’s spread out) updating Echoes, even though it demonstrably already worked. It had a couple hiccups, sure, but I could have fixed those without rewriting all the documentation and unit tests. But hey, now we have more documentation and unit tests!
When I discovered constructor inlining, I dropped everything to rewrite Runaway’s math classes. They already worked fine, but nooo, the code was a little bit verbose, we couldn’t have that!
With new math classes available and a vague sense that I was overcomplicating space, I stumbled across the term orthonormal basis. And that inspired me to rethink the concepts of space, collisions, moving, and jumping all at once. I’m going to need to write a whole new “how space works in Run” post…
To take advantage of all this new code, I wrote the demo app shown above. It took about as long as the libnoise demo, but at least this time I plan to keep using it.
When first making the demo, I enabled one system at a time, so that I’d only have to debug one section of code at a time. Eventually, I decided just to enable all the systems from the Run 1 beta, even knowing I’d immediately get dozens if not hundreds of errors. I figured it’d let me keep stalling for a while longerlocate lots of bugs all at once.
I estimate that fixing that last batch of bugs will take at least… oh. Uh, they’re already done. Took less than a week. I guess there was a benefit to all that feature creepcareful planning and solid mathematical foundations.
Except, that is, for one single system. This system was especially complicated, and since I wanted to post this post, I left it commented out. Once I get this system working, I think that will be everything: I’ll be unable to keep stallingready to work on Run 1.
I’ll be ready to polish the wonky character animations, make the motion feel more like it used to, and, of course, update the level load system to handle Infinite Mode levels, all those things I’ve been saying I want to do. But first, I need to fix up this one complicated system.
So which system is it? It is, in fact…
…the level loading system. Also, the only reason it’s so broken is because I made those other changes to how loading works. Fixing the errors will automatically also make the system compatible with Infinite Mode.
Huh. I guess that means I’m already done stalling. No more redoing old features, I’m officially now working on the thing that started this entire multi-year rabbit hole. Or maybe I could go implement rotors first… One more detour…
Last time, I said I was done with rabbit holes. I was wrong. Turns out, after escaping one rabbit hole, I promptly fell down the next.
First it was threads. I spent all of March working on an app to demonstrate threads in action. Sure I probably spent more time on it than strictly necessary, but I got a cool demo out of it. Plus, working on a practical example helps catch bugs and iron out rough edges.
With that done, I turned my focus to updating the 21 C++ libraries Lime uses. (Well, 19 out of the 21, anyway.) I forget exactly why I decided it needed to be done then and there, but I think a big part was the fact that people were raising concerns about large unresolved problems in OpenFL/Lime, and this was one I could solve. Technically I started last year, and this was me rolling up my sleeves and finishing it.
A couple stats for comparison: I spent ~4 months working on threads, and produced 53 commits. I spent ~2.5 months working on the C++ libraries, and produced 102 commits. And that’s why you can’t measure effort purely based on “amount of code written.” The thread classes took far more effort to figure out, but a lot of that effort was directed into figuring out which approach to take, and I only committed the version I settled on. The alternative options silently vanished into the ether.
All the while, I spent bits of time here and there working on issue reports. Tracking down odd bugs, adding small features, stuff like that. There are several changes in the pipeline, and if you want the technical details, check out my other post. (Scroll to the bottom for more on the big 19-library update.)
Lime hasn’t received a new release version in over a year, even though development has kept going the whole time. As we gear up for the next big release, I wanted to take a look at what’s on the way.
Merged changes
These changes have already been accepted into the develop branch, meaning they’ll be available in the very next release.
Let’s cut right to the chase. We have a bunch of new features coming out:
80f83f6 by joshtynjala ensures that every change submitted to Lime gets tested against Haxe 3. That means everything else in this list is backwards-compatible.
#1456 by m0rkeulv, #1465 by me, and openfl#2481 by m0rkeulv enable “streaming” music from a file. That is to say, it’ll only load a fraction of the file into memory at a time, just enough to keep the song going. Great for devices with limited memory!
Usage: simply open the sound file with Assets.getMusic() instead of Assets.getSound().
#1519 by Apprentice-Alchemist and #1536 by me update Android’s minimum-sdk-version to 21. (SDK 21 equates to Android 5, which is still very old. Only about 1% of devices still use anything older than that.) We’re trying to strike a balance between “supporting every device that ever existed” and “getting the benefit of new features.”
Tip: to go back, set <config:android minimum-sdk-version="16" />.
Usage: since AS3 never supported pitch, OpenFL probably won’t either. Use Lime’s AudioSource class directly.
81d682d by joshtynjala adds Window.setTextInputRect(), meaning that your text field will remain visible when an onscreen keyboard opens and covers half the app.
#1552 by me adds a brand-new JNISafety interface, which helps ensure that when you call Haxe from Java (using JNI), the code runs on the correct thread.
Personal story time: back when I started developing for Android, I couldn’t figure out why my apps kept crashing when Java code called Haxe code. In the end I gave up and structured everything to avoid doing that, even at the cost of efficiency. For instance, I wrote my android6permissions library without any callbacks (because that would involve Java calling Haxe). Instead of being able to set an event listener and receive a notification later, you had to actively call hasPermission() over and over (because at least Haxe calling Java didn’t crash). Now thanks to JNISafety, the library finally has the callbacks it always should have had.
2e31ae9 by joshtynjala stores and sends cookies with HTTP requests. Now you can connect to a server or website and have it remember your session.
#1509 by me makes Lime better at choosing which icon to use for an app. Previously, if you had both an SVG and an exact-size PNG, there was no way to use the PNG. Nor was there any way for HXP projects to override icons from a Haxelib.
Developers: if you’re making a library, set a negative priority to make it easy to override your icon. (Between -1 and -10 should be fine.) If you aren’t making a library and are using HXP, set a positive priority to make your icon override others.
…But that isn’t to say we neglected the bug fixes either:
#1485 by justin-espedal fixes a widely-reported crash on iOS. On specific devices, the garbage collector would be initialized incorrectly, causing the app to crash on startup nearly 100% of the time.
2160962 by joshtynjala adds a missing framework on iOS. Before this, Lime wouldn’t compile to iOS at all. (Well, at least until you added Metal.framework yourself. But it’s much better if Lime does it for you.)
For context, HashLink is the new(er) virtual machine for Haxe, intended to replace Neko as the “fast compilation for fast testing” target. While I find compilation to be a little bit slower than Neko, it performs a lot better once compiled.
Prior to now, Lime compiled to HashLink 1.10, which was three years old. Pull request #1517 covers two versions and three years’ worth of updates. From the release notes, we can look forward to:
captured stack for closures (when debugger connected)
and more!
(As someone who uses HashLink for rapid testing, I’m always happy to see debugging/profiling improvements.)
Apprentice-Alchemist put a lot of effort into this one, and it shows. Months of testing, responding to CI errors, and making changes in response to feedback.
Lime has several pull requests that are – as of this writing – still in the “request” phase. I expect most of these to get merged, but not necessarily in time for the next release.
#1538 by me fixes errors that came up if you didn’t cd to an app’s directory before running it. Now you can run it from wherever you like.
#1500 by me modernizes the Android build process. This should be the end of that “deprecated Gradle features were used” warning.
Submodule update
#1531 by me is another enormous change that gets its own section. By far the second biggest pull request I’ve submitted this year.
Lime needs to be able to perform all kinds of tasks, from rendering image files to drawing vector shapes to playing sound to decompressing zip files. It’s a lot to do, but fortunately, great open-source libraries already exist for each task. We can use Cairo for shape drawing, libpng to open PNGs, OpenAL to play sound, and so on.
In the past, Lime has relied on a copy of each of these libraries. For example, we would open up the public SDL repository, download the src/ and include/ folders, and paste their contents into our own repo. Then we’d tell Lime to use our copy as a submodule.
This was… not ideal. Every time we wanted to update, we had to manually download and upload all the files. And if we wanted to try a couple different versions (maybe 1.5 didn’t work and we wanted to see if 1.4 was any better), that’s a whole new download-upload cycle. Plus we sometimes made little customizations unique to our copy repos. Whenever we downloaded fresh copies of the files, we’d have to patch our customizations back in. It’s no wonder no one ever wanted to update the submodules!
If only there was a tool to make this easier. Something that can download files from GitHub and then upload them again. Preferably a tool capable of choosing the correct revision to download, and merging our changes into the downloaded files. I don’t know, some kind of software for controlling versions…
(It’s Git. The answer is Git.)
There was honestly no reason for us to be maintaining our own copy of each repo, much less updating our copies by hand. 20 out of Lime’s 21 submodules have an official public Git repo available, and so I set out to make use of them. It took a lot of refactoring, copying, and debugging. A couple times I had to submit bug reports to the project in question, while other times I was able to work around an issue by setting a specific flag. But I’m pleased to announce that Lime’s submodules now all point to the official repositories rather than some never-updated knockoffs. If we want to use an update, all we have to do is point Lime to the newer commit, and Git will download all the right files.
But I wasn’t quite done. Since it was now so easy to update these libraries, I did so. A couple of them are still a few versions out of date due to factors outside of Lime’s control, but the vast majority are fully up-to-date.
Other improvements that happened along the way:
More documentation, so that if anyone else stumbles across the C++ backend, they won’t be as lost as I was.
Support for newer Android NDKs. Well, NDK 21 specifically. Pixman’s assembly code prevents us from updating further. (Still better than being stuck with NDK 15 specifically!)
Updating zlib fixes a significant security issue (CVE-2018-25032).
Looking forward
OpenFL and Lime are in a state of transition at the moment. We have an expanded leadership team, we’ll be aiming for more frequent releases, and there’s plenty of active discussion of where to go next. Is Lime getting so big that we ought to split it into smaller projects? Maybe! Is it time to stop letting AS3 dictate what OpenFL can and can’t do? Some users say so!
Stay tuned, and we’ll find out soon enough. Or better yet, join the forums or Discord and weigh in!
This is a haxe port of libnoise, the coherent noise library. The port is almost complete, only the gradient and noise2D utilities are missing.
Every now and then, I try out a new library and find something cool. libnoise is one such library, so it’s time for a Haxelib review!
In this post, I’ll explain what libnoise offers, how good it is at its job, and where it has room for improvement. Plus whatever else I think of along the way.
As its description states, libnoise is a tool for generating coherent noise. To keep things simple, I’m going to pretend “coherent noise” means “grayscale images.” But if you want to dig deeper, Rick Sidwell has an excellent rundown.
Let’s begin with some coherent noise.
This cloud-like image is what’s called Perlin noise, and it’s just one of many patterns libnoise can make.
Generators
Each of libnoise’s generators creates a distinct pattern. Four of these generators are dead simple.
Const a solid color. It can be any shade, though this demo keeps it simple.
Cylinder and Sphere create repeating gradients centered on the top-left corner. Because the demo is 2D, they barely resemble their namesakes, so you just have to imagine a bunch of 3D spheres nested inside one another, or a bunch of nested cylinders centered on the left edge.
Checker creates a checkerboard pattern on the pixel level. One pixel is white, the next is black, the next is white, and so on.
The other four involve randomness.
Perlin generates (what else?) Perlin noise. Not going to go into depth on how it works; see Rick Sidwell’s post for that. This example uses 8 octaves (fractal layers), meaning there’s extra detail but it takes longer to draw.
Billow creates what I’d describe as wandering lines, but under the hood it’s very similar to Perlin. If you compare the source code side-by-side, you’ll notice the algorithm is identical except for a single Math.abs() call on line 35.
RidgedMultifractal also creates wandering lines. I guess you could also call them “ridges”? That’s probably how it got that name. If you look at the source code, you’ll see that it’s also pretty similar to Perlin, though with a few more differences. In the end, it comes out looking like the inverse of Billow.
Voronoi creates a Voronoi diagram. This is a way of partitioning space based on a set of “seed” points, where every pixel is assigned to the closest seed… You know what? I can’t fit a full explanation here, so go read the article for the details.
3D patterns
I hinted at this already, but libnoise is built to generate 3D patterns. You can set the Z coordinate to 0 – as I did – and just make 2D images, but each of these 2D images is a cross-section of the full pattern. That’s why libnoise calls the classes Cylinder and Sphere rather than Line and Circle: the full 3D pattern really is cylindrical/spherical.
Voronoi, Perlin, Billow, and RidgedMultifractal all subtly change because of this. Each pixel in these patterns is influenced by points outside the 2D plane, meaning they appear different than if we were using a 2D algorithm to generate them. (Because the 2D algorithm would only calculate points in the 2D plane.) But it’s very hard to tell just by looking at a single image of them.
Here’s a way to see the difference. If we took different cross-sections of a cylinder, we could see its lines start to curve.
If we kept going until 90°, it would look fully circular, just like Sphere.
Operators
libnoise’s generators make the basic images, but its operators are where things get interesting. They modify those base images in all kinds of ways. Inverting, combining, you name it.
To get a good sense of how an operator works, it helps to see the input and output side-by-side. The downside is, it requires splitting up the canvas and cropping each input and output. To view more of a pattern, hover over it and click the “expand” button in the bottom corner.
Unary operators
The simplest operators are those that only take a single image as input, like the Rotate operator shown above. Most unary operators either perform simple arithmetic or move the pattern somehow.
The above three perform arithmetic on the brightness of each pixel. libnoise represents brightness using a value between -1 (black) and 1 (white).
Abs takes the absolute value of the brightness, so anything below 0 (gray) becomes positive. After this, no part of the pattern will be darker than gray.
Clamp sets a minimum and maximum value. This demo uses -0.5 (dark gray) as the minimum and 0.5 (light gray) as the maximum, but other programs could adjust further. This cuts out the shadows and highlights but leaves the midtones untouched.
Rotate, Scale, and Translate do exactly what their names imply. Though they can rotate, scale, and translate in any direction, this demo only includes two options each.
Turbulence moves pixels in random directions. “Low” and “high” refer to the maximum distance pixels are allowed to move. However, there’s a bit more to it than that, if we look closely. Fortunately, libnoise allows applying an operator to an operator, so we can Scale the Turbulence.
While it normally looks grainy, if we zoom in enough times, the turbulence starts to look surprisingly smooth. It turns out that it doesn’t move pixels completely at random. There’s an underlying pattern, and that pattern is called… Perlin noise.
Yes indeed, the Turbulence class generates Perlin noise to figure out where it should move each pixel. Perlin noise is a type of gradient noise, and gradient noise always looks smooth when you zoom in. The trick is that the Turbulence class does not zoom in by default, creating the illusion that it isn’t smooth.
Binary operators
libnoise’s two-input operators all perform arithmetic. As a reminder, libnoise represents brightness using a value between -1 (black) and 1 (white).
Add takes the sum of two patterns. If both inputs are bright, the output will be even brighter. If both are dark, the output will be even darker.
Subtract takes the difference. It’s the same as if you inverted the second pattern before adding.
Multiply takes the product of the numbers. Since we’re multiplying numbers less than 1, they always tend towards 0, and we end up with a lot of gray.
Average looks like Add but grayer, because that’s exactly what it is: (a + b) / 2. Strangely libnoise doesn’t include this operator, so I implemented it myself for demo purposes.
Finally, libnoise has two three-input operators, and they’re both very similar. Their output is always a combination of pattern 1 and pattern 2, and they use pattern 3 to decide what combination.
Select is all-or-nothing. If pattern 3 is darker than a certain value, it selects pattern 1 and shows that. If pattern 3 is above that threshold, it selects pattern 2.
Blend interpolates between the first two patterns, using pattern 3 to decide how much of each to blend. If pattern 3 is dark, it’ll use more of pattern 1. If pattern 3 is light, it’ll use more of pattern 2.
Select also has a fallOff value that makes it do a little of both. If a number is close to the threshold value, it blends just like Blend. If the number is farther away, it selects like normal.
More patterns
Hopefully now you have a good idea of what each generator and operator does, so it’s time for some more interesting combinations. But first, it’s time to take the training wheels off:
The UI is simple to explain, if unwieldy. Hover over a section of canvas to see a dropdown. Pick an option from the dropdown to fill that part of the canvas. Scroll all the way to the bottom of the dropdown if you want to split the canvas up (or put it back together).
With that out of the way, here are some interesting patterns I’ve come across. Try them out, and be sure to try switching up the generators. You can always revert your changes by clicking the button again.
What patterns can you come up with? If you make something you want to share, you can copy it with ctrl+C, and others can paste it in with ctrl+V. Feel free to post it in the comments, but make sure to insert four spaces in front of your code. If you don’t, WordPress could mess up your formatting.
I was supposed to be reviewing this library, not just showing off a bunch of cool patterns. …Though on the other hand, showing the cool patterns gives you an idea of what the library is good at. Isn’t that half the point of a review?
Well, perhaps I should do a traditional review too. I’d describe libnoise as functional and well-designed, but lacking in documentation and not very beginner-friendly.
Let’s look at some code. Here’s just about the simplest way you could implement the “minimum of two gradients” sample. (As a reminder, that’s Min, Billow, and Cylinder.)
//Step 1: define the pattern.
var billow:Billow = new Billow(0.01, 2, 0.5, seed, HIGH);
var cylinder:Cylinder = new Cylinder(0.01);
var min:Min = new Min(billow, cylinder);
//Step 2: create something to draw onto.
var bitmapData:BitmapData = new BitmapData(512, 512, false);
//Step 3: iterate through every pixel.
for(x in 0...bitmapData.width) {
for(y in 0...bitmapData.height) {
//Step 3a: Get the pixel value, a number between -1 and 1. Use a z coordinate of 0.
var value:Float = min.getValue(x, y, 0);
//Step 3b: Convert to the range [0, 255].
var brightness:Int = Std.int(128 + value * 128);
if(brightness < 0) {
brightness = 0;
} else if(brightness >= 256) {
brightness = 255;
}
// Step 3c: Convert to a color.
var color:Int = brightness << 16 | brightness << 8 | brightness;
//Step 3d: Save the pixel color.
bitmapData.setPixel32(x, y, color);
}
}
//Step 4: display and/or save the bitmap.
addChild(new Bitmap(bitmapData));
libnoise makes steps 1 and 3a easy enough, but you have to fill in all the other steps yourself. That’s fine – maybe even desirable – for advanced users. However, a new user who just wants to try it out isn’t going to appreciate the extra work. The new user would like to be able to do something like this:
//Step 1: define the pattern.
var billow:Billow = new Billow(0.01, 2, 0.5, seed, HIGH);
var cylinder:Cylinder = new Cylinder(0.01);
var min:Min = new Min(billow, cylinder);
//Step 2: make the drawing.
var noise2D:Noise2D = new Noise2D(512, 512, min);
var bitmapData:BitmapData = noise2D.getBitmapData(GradientPresets.grayscale);
//Step 3: display and/or save the bitmap.
addChild(new Bitmap(bitmapData));
Room for improvement
Here’s what I’d work on if I ever began using libnoise seriously.
Finish the port. The GradientPresets and Noise2D classes I mentioned would make it much easier to add color and export images. They existed in the original version(s) of libnoise, but didn’t survive the port.
The author explained that they didn’t want to tie libnoise to outside libraries (like OpenFL), but I’d say it’s more than worth it. Besides, conditional compilation makes it easy to support OpenFL without depending on it.
More generators. If you ignore the fluff, libnoise only implements two noise algorithms: Perlin and Voronoi. There are plenty more algorithms out there, including Simplex, an improvement on Perlin noise whose patent recently expired, and Worley noise, resembling a textured Voronoi diagram.
libnoise already implements value noise under the hood, but doesn’t make it available to the user. It’d be very easy to add.
And there’s no need to limit the library to coherent noise. Why not pure static?
More options for existing operators. Turbulence, for instance, can’t be scaled without applying an Scale operator to the whole image. But what if you want the zoomed-in turbulence effect without zooming in on the underlying pattern?
More operators. I made a custom Average operator for the demo, but that should be in the base library. Besides that, I’d like to see operators to blur, lighten, or darken the image.
Better performance, if possible.
Better documentation and code style. libnoise is a port of a port, and each time it was ported, most of the comments were lost or replaced. (Nor were all of the surviving comments accurate, due to overzealous copy-pasting.)
That’s all that comes to mind, which is probably a good sign. libnoise is entirely usable as-is, even if there’s work left to do.
Comparing libnoise to other libraries
I’m aware of four different noise libraries in Haxe. libnoise, MAN-Haxe,noisehx, and hxNoise. (Interesting coincidence: all four are from 2014-2016 and haven’t been updated since.)
Let’s look at what each library brings to the table.
noisehx offers Perlin noise, and that’s it. It’s also the only library to offer both 2D and 3D Perlin noise, meaning you can save processing time if you only need a 2D image.
hxNoise offers diamond-square noise as well, which basically functions as a faster but lower-quality version of Perlin noise. Its Perlin noise is 3D but its diamond-square noise is 2D.
MAN-Haxe doesn’t offer Perlin noise at all, though it offers two other types of noise that resemble it. It also offers Worley noise and a couple maze-generation algorithms. That last one is why it’s called “Mazes And Noises.” Oh, and all of this is 2D.
I’d call MAN-Haxe the most grounded of the libraries. It’s built for one specific purpose: to generate maps for HaxeFlixel games. It just incidentally happens to do images too. If your goal is to generate 2D rectangular maps for a 2D game and you happen to be using HaxeFlixel, then MAN-Haxe is right for you.
None of these alternative libraries offer operators, which means libnoise can generate a greater variety of images. That said, it isn’t like libnoise’s operators are particularly complicated. If you wanted to invert hxNoise’s diamond-square noise, you could do that yourself.
In my last status update, I said I’d (1) update Android libraries and then (2) add Infinite Mode to the HTML5 version. As I mentioned in an edit, that first step took a single day. Then the second took… three months. So far.
It all unfolded something like this:
I wanted to add Infinite Mode.
The loading code I used for Explore Mode isn’t up to the task of handling procedurally-generated levels. (Plus I have other plans that require seamless loading.) So I put step 1 on pause in order to write better loading code.
I realized/decided that good loading code needs to support threads. You don’t have to use them, but they should be an option. The good news is, Lime already supports threads. The bad news: not in HTML5. So I put step 2 on hold as I worked to update Lime.
Every time I thought I’d reached the bottom of this rabbit hole, I found a way to keep digging. But I’m happy to announce that instead of proceeding with step 6, I’ve turned around and begun the climb back out:
As of today, I finished combining the ideas from steps 3-5 above, which in theory fixes threads in Lime once and for all. I’m sure the community will suggest changes, but I can hopefully shift most of my focus.
Use threads/virtual threads to achieve my vision of flexible and performant loading.
Use this new flexibility to load Infinite Mode’s levels.
I’m also well aware that Run Mobile doesn’t work on Android 12. I’ve been too busy with threads to take a look, but now that I’m (very nearly) done, I really ought to do that next. Update: I did! The fixed version is available on Google Play.






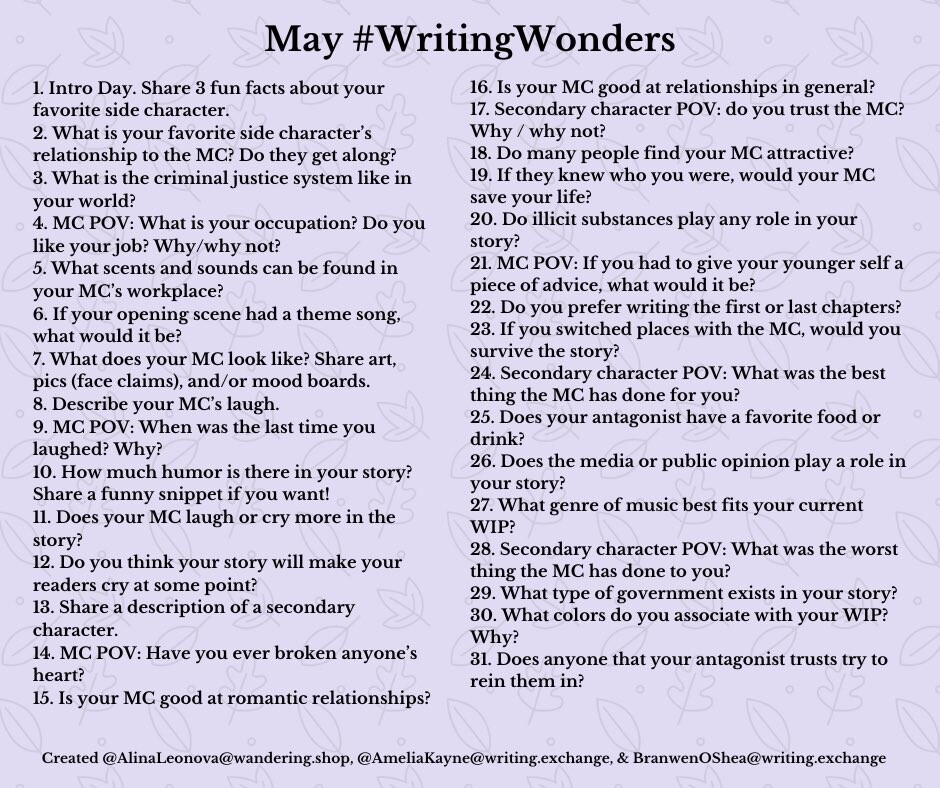
![[The Runner stares aghast at the Chemist, who appears to have taken apart a clock] / Runner: Well, maybe I'll just find somewhere else to live. / Chemist: Could you, please? That'd benefit us both. / [A picture of some clouds] / [A boat is docked behind the Runner, who stands in front of a doorway] / Sailor: Sis? / Runner: Yeah, I need a place to stay... for a while / Sailor: oh](/wp-content/uploads/somewhere_else_to_live_imanoutlawontherun_preview.jpg)








![I genuinely believe that if you do not learn from your mistakes, they will come back worse and worse / Not in a karma type of way, but in a logical way / [Luke holds an near-empty glass; to his left are two already-finished glasses; to his right are two still-full glasses marked "poison"] / "Why does this keep happening?" / Being ignorant to what changes you need will only make a hard life](/wp-content/uploads/luke_mistakes.jpg)

![The place I lived in was near Windsor Castle / When I came home one night there were 2 guards drinking in the kitchen with some housemates / It was a fairly loud house / [Luke, appearing half asleep, stares blankly at the guards] / [Luke continues blankly staring as he begins to walk away] / [Luke continues blankly staring as he walks out of sight]](/wp-content/uploads/luke_guards.jpg)
![I don't have to classify anything / I'm just very confused / Dropping expectations / Feeling like myself / Looking internally / [Luke is lying down with his mouth wide open; his eyes bulge out of his head and bend 180° down to look inside]](/wp-content/uploads/luke_internal.jpg)
